# 浏览器渲染原理
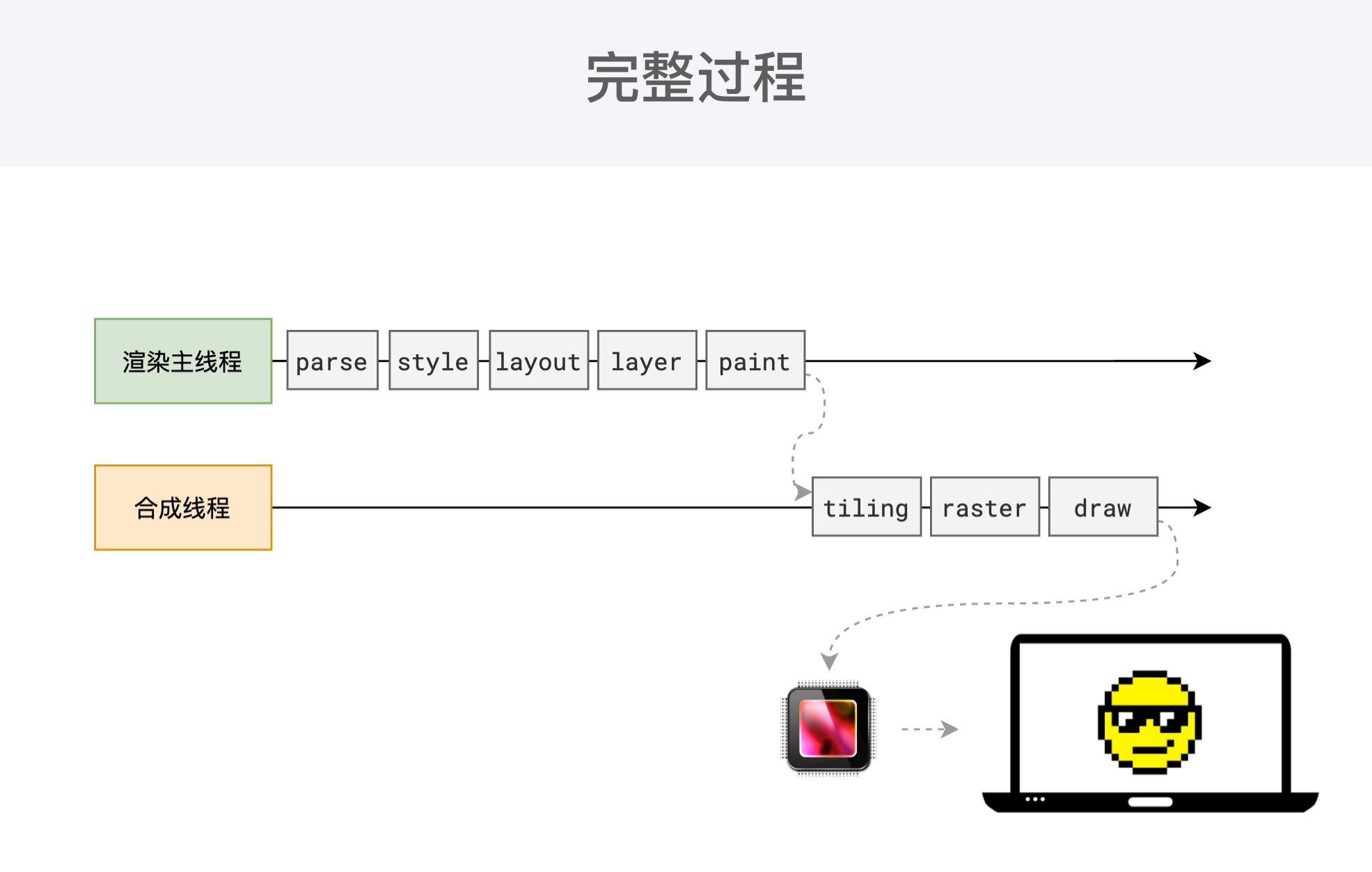
当浏览器的网络线程收到HTML文档后,会产生一个渲染任务,并将其传递给渲染主线程的消息队列,在事件循环机制的作用下,渲染主线程取出消息队列的渲染任务,开始渲染流程。
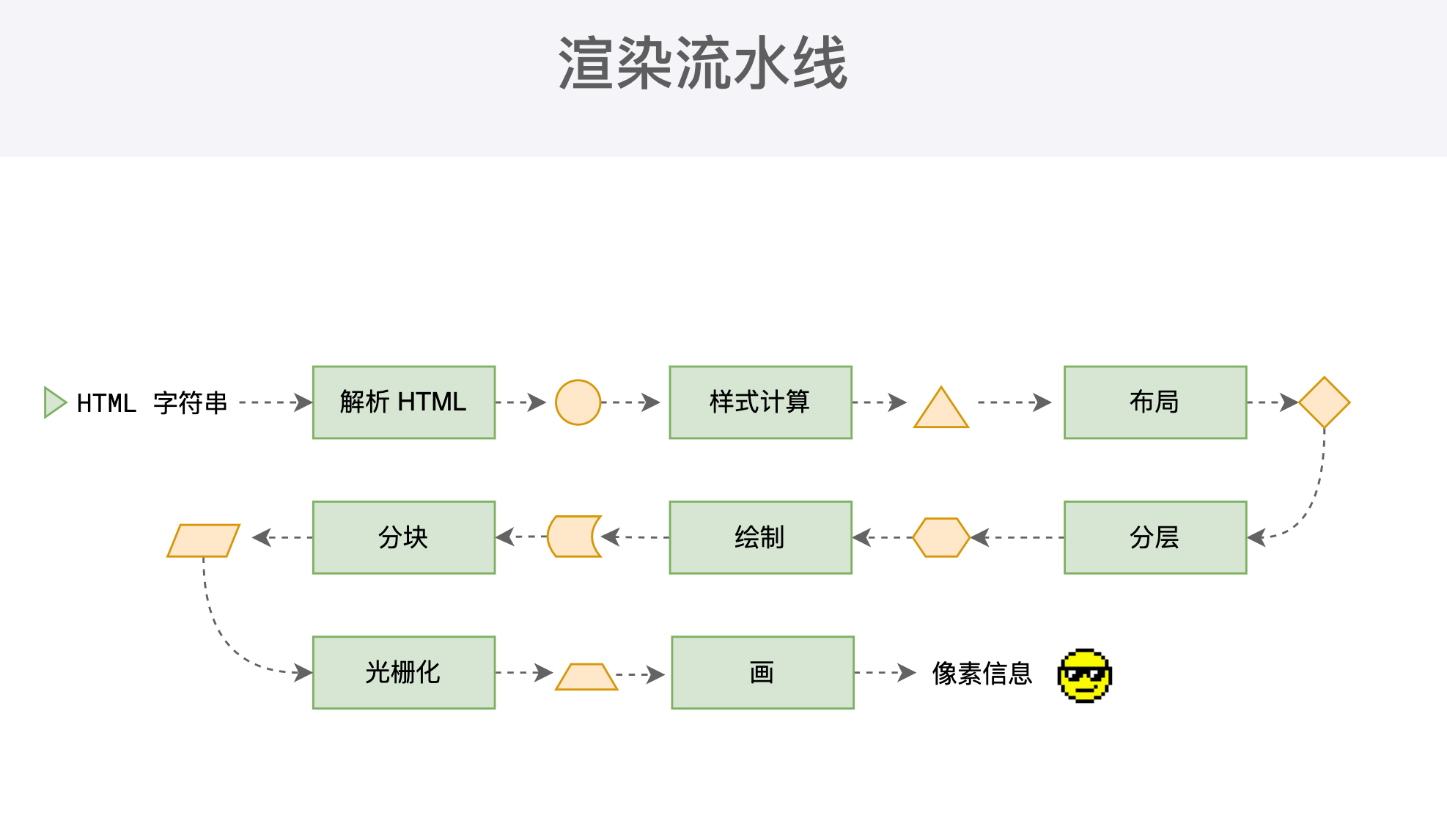
整个渲染流程分为多个阶段,分别是:HTML解析、样式计算、布局、分层、绘制、分块、光栅化、画。每个阶段都有明确的输入输出,上一阶段的输出会成为下一阶段的输入
渲染的第一步解析 HTML
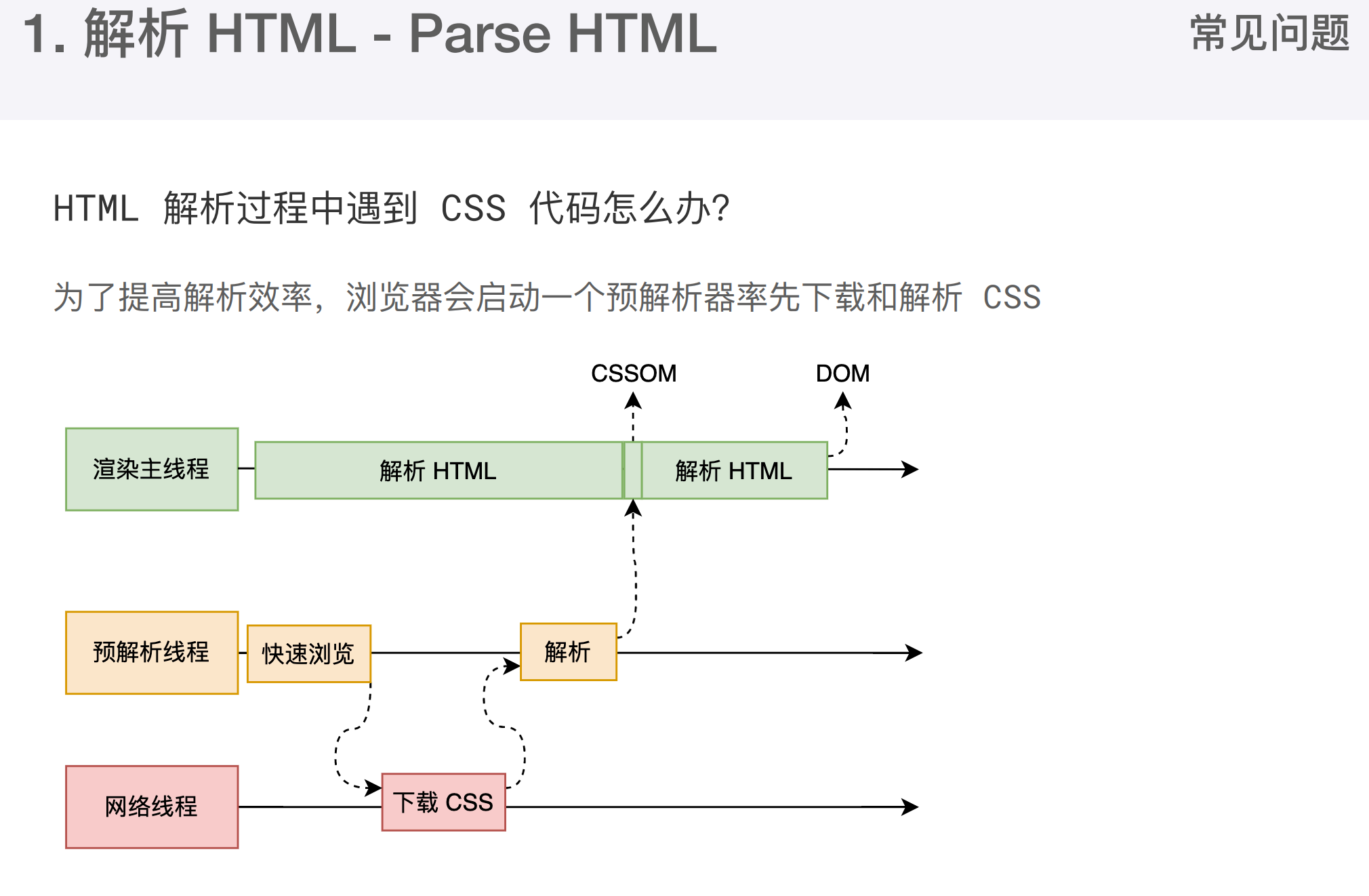
解析过程中遇到css解析css,遇到js执行js。为了提高解析效率,浏览器在开始解析前,会启动一个预解析的线程,率先下载HTML中的外部 CSS文件 和外部的 JS 文件
如果主线程解析到 link 位置,此时外部的CSS文件还没有下载解析好,主线程不会等待,继续解析后续的HTML。这是因为下载和解析CSS的工作是在预解析线程中进行的,这就是CSS不会阻塞HTML解析的根本原因
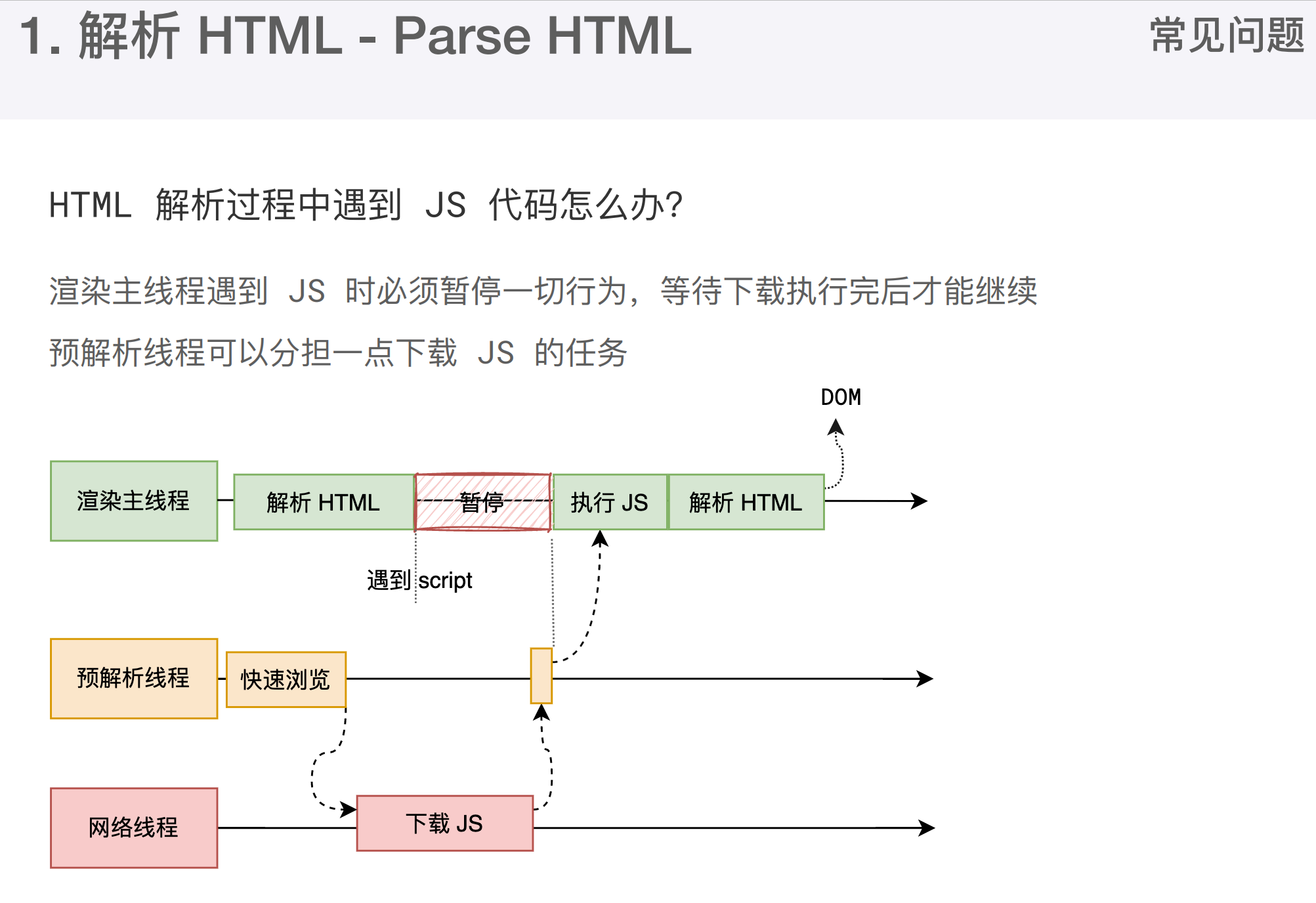
如果主线程解析到script位置,会停止解析 HTML,转而等待JS文件下载好,并将全局代码解析执行完成后才能继续解析HTML。这是因为JS代码的执行过程可能会修改当前的DOM树,所以DOM树的生成必须
暂停。这就是JS会阻塞HTML解析的根本原因
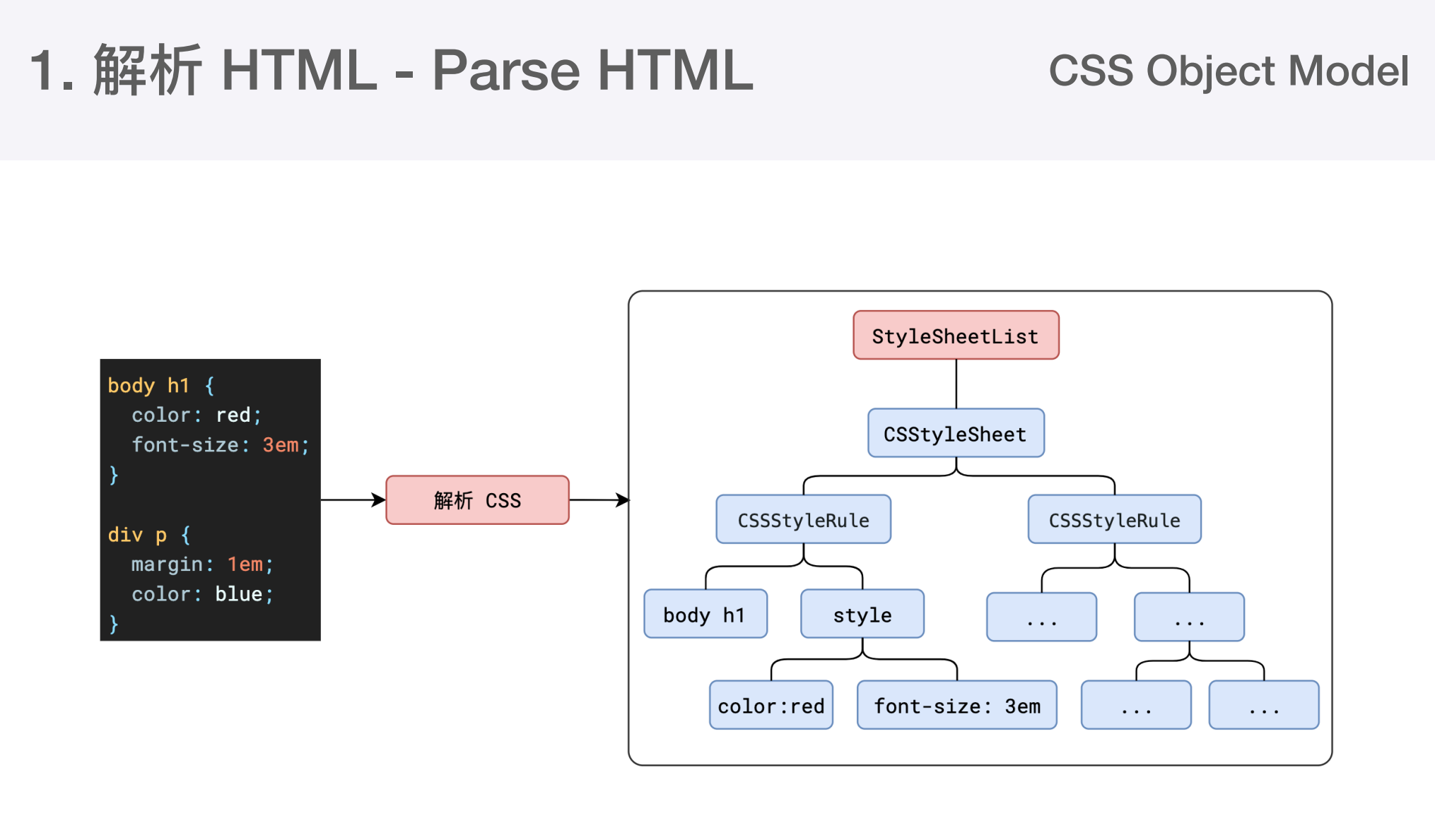
第一步完成后会得到DOM树和CSSOM树, 浏览器的默认样式、内部样式、行内样式均会包含在CSSOM树中。
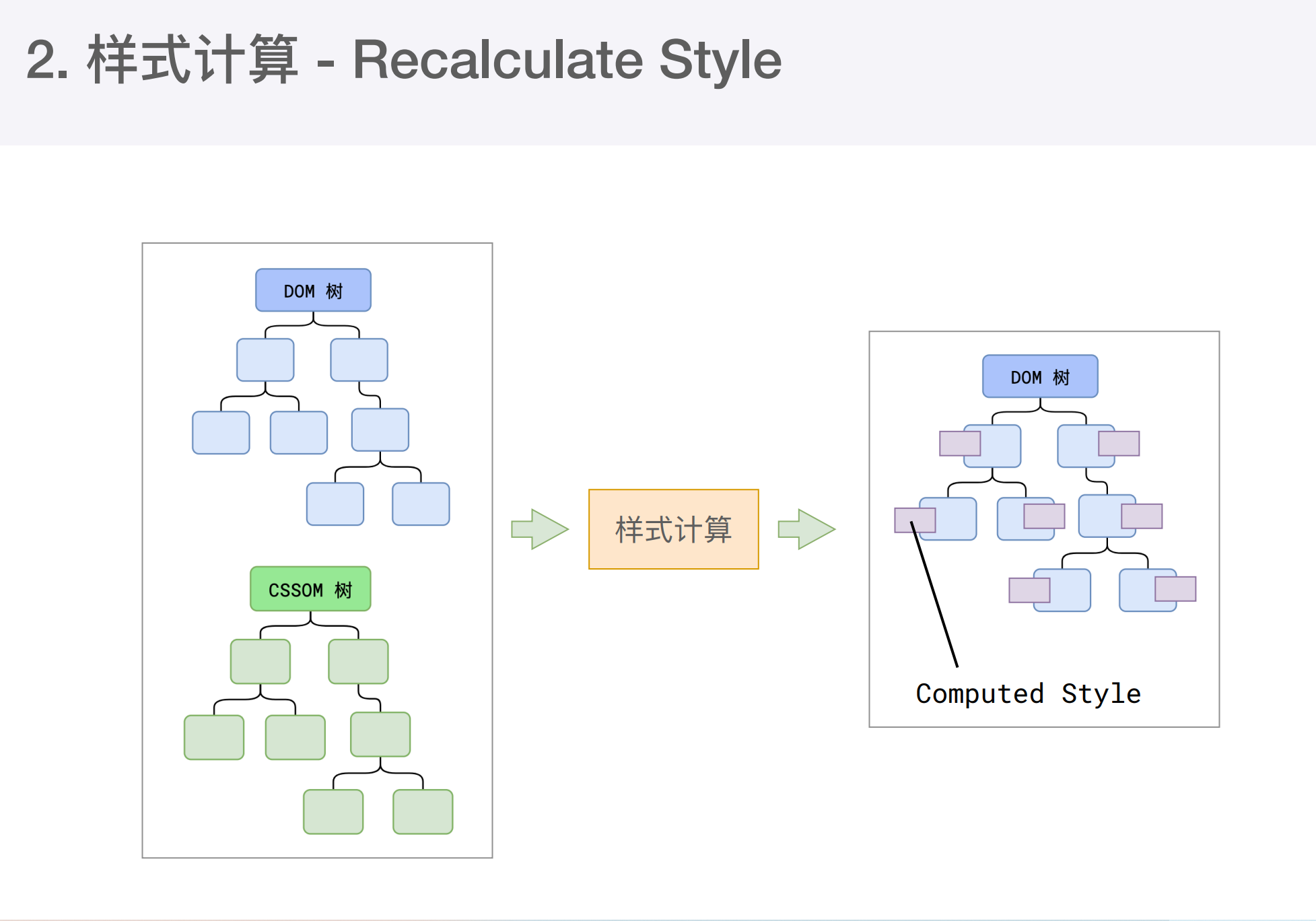
渲染的下一步是样式计算
主线程会遍历得到的DOM树,依次为树中的每个节点计算得出它的最终样式,称之为Computed Style。这一过程中,很多预设值会变成绝对值,比如red->rgb(255,0,0);相对单位会变成绝对单位 如em->px。 得到一颗带有样式的DOM树
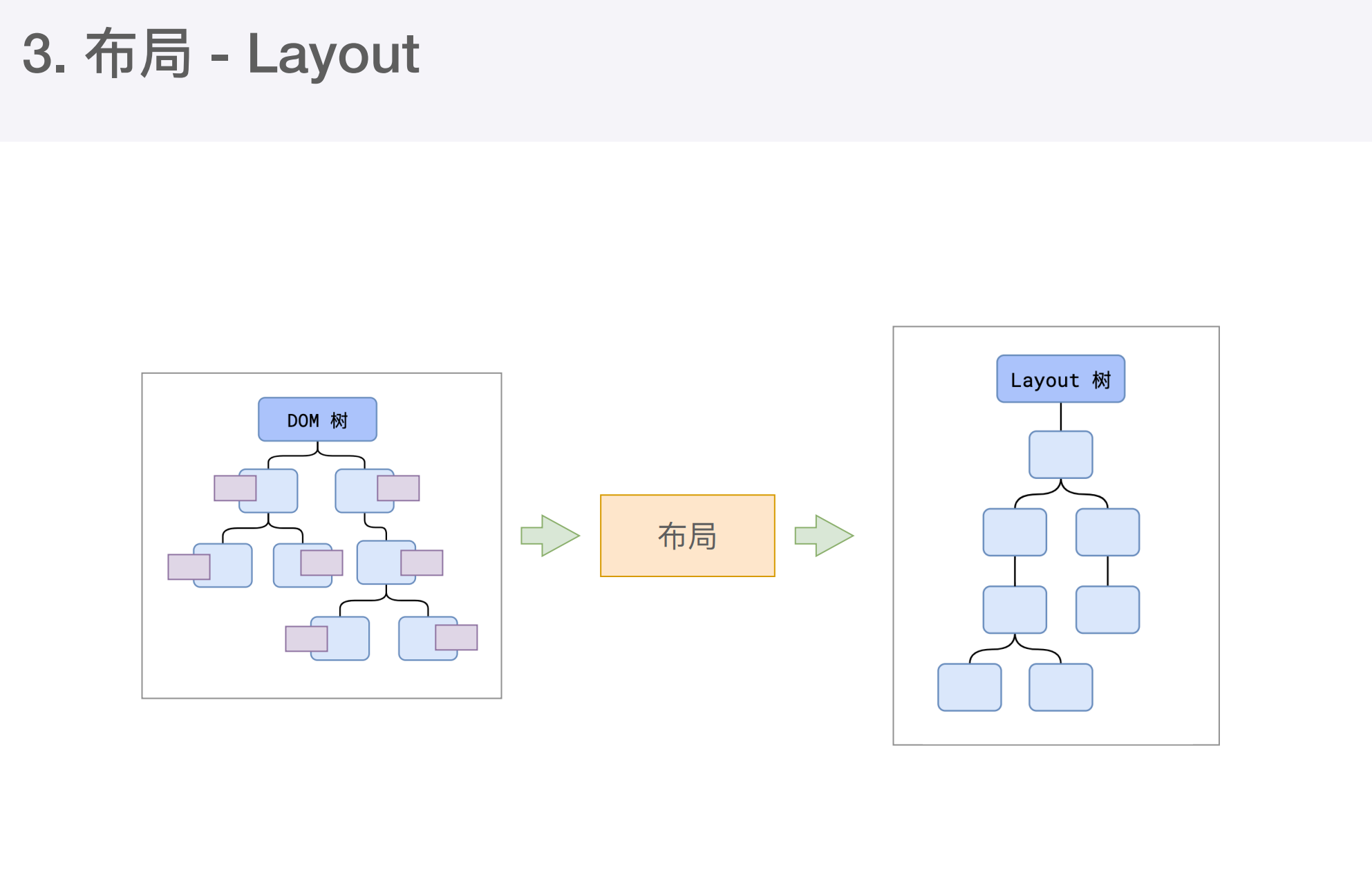
接下来布局
布局阶段会依次遍历DOM树中的每一个节点,计算每个节点的几何信息。例如宽高,相对包含块的位置。
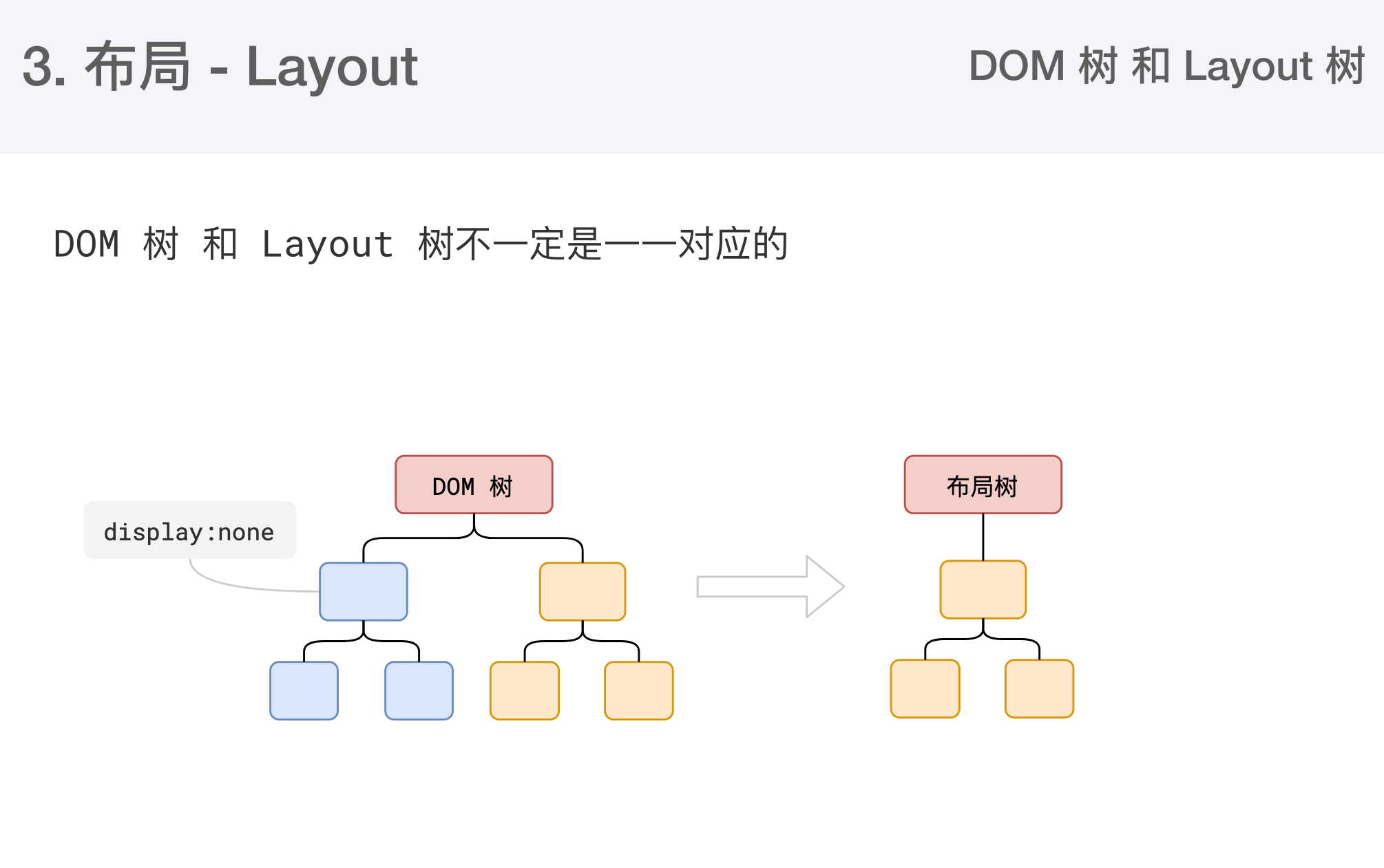
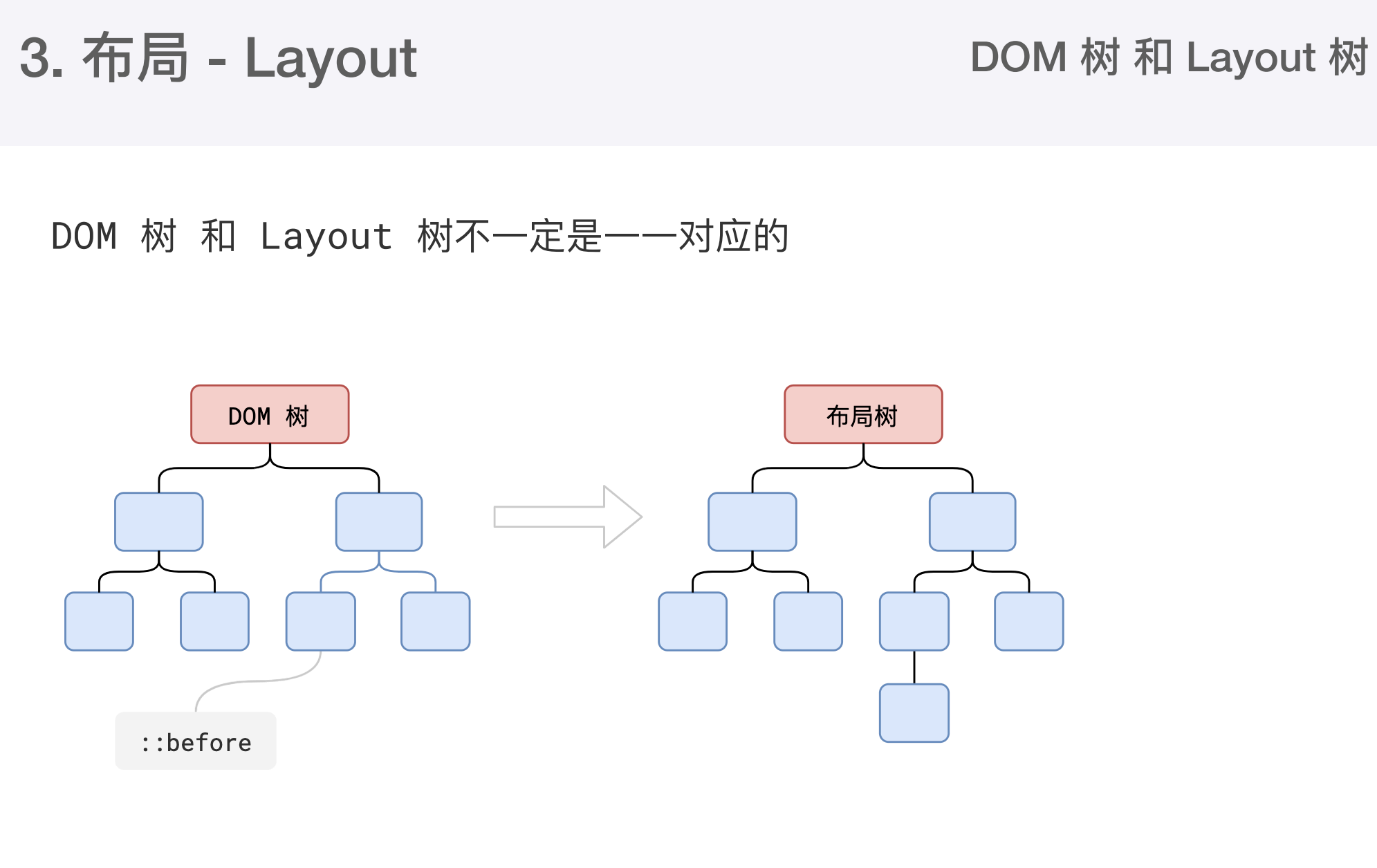
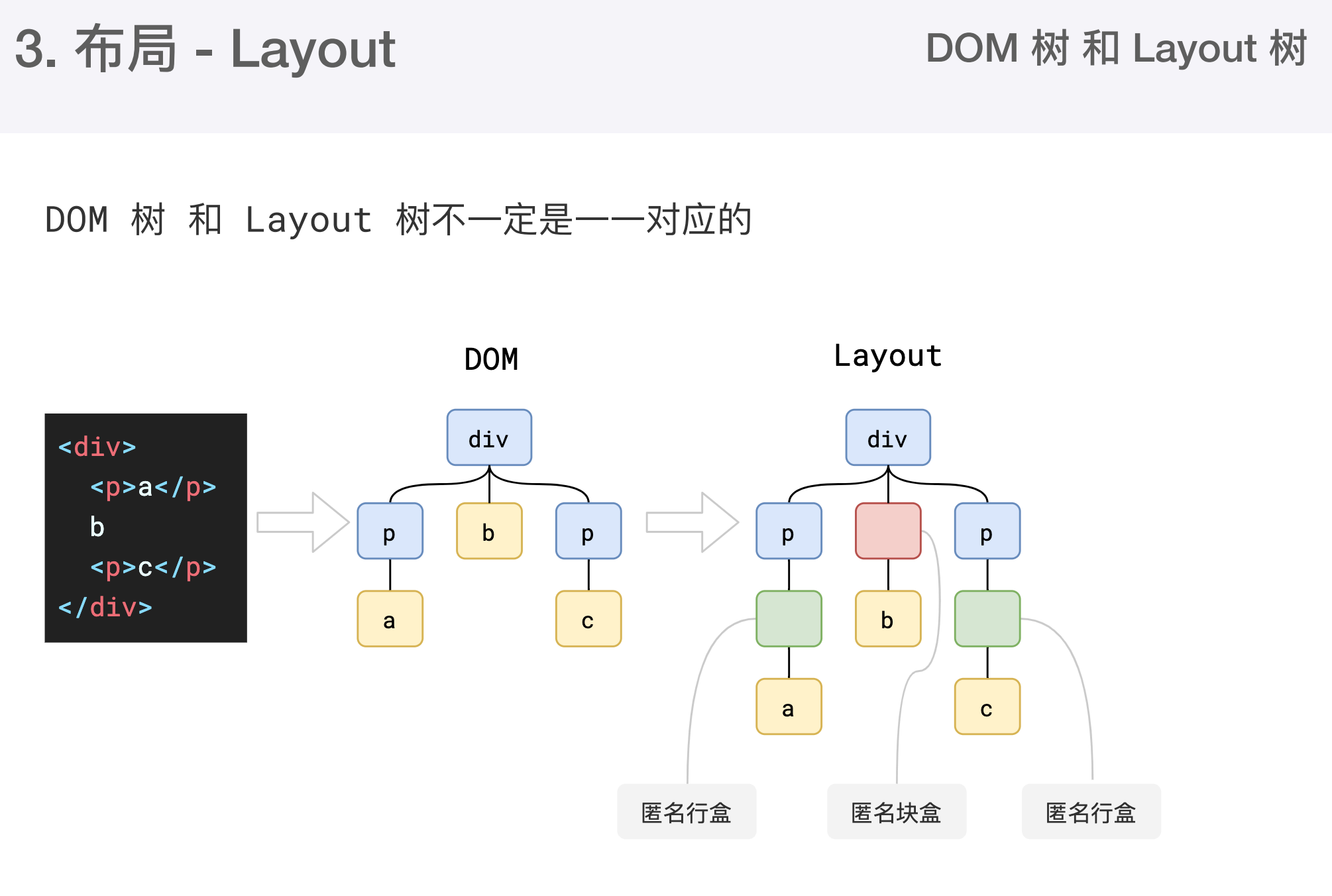
大部分时候DOM树和布局树并非一一对应
- 比如
display:none的节点没有几何信息,因此不会生成到布局树 - 比他使用伪元素选择器,虽然DOM树中不存在这些伪元素,但他们有集合信息,所以会生成到布局树中
- 匿名行盒、匿名块盒等都会导致DOM树和布局树无法一一对应
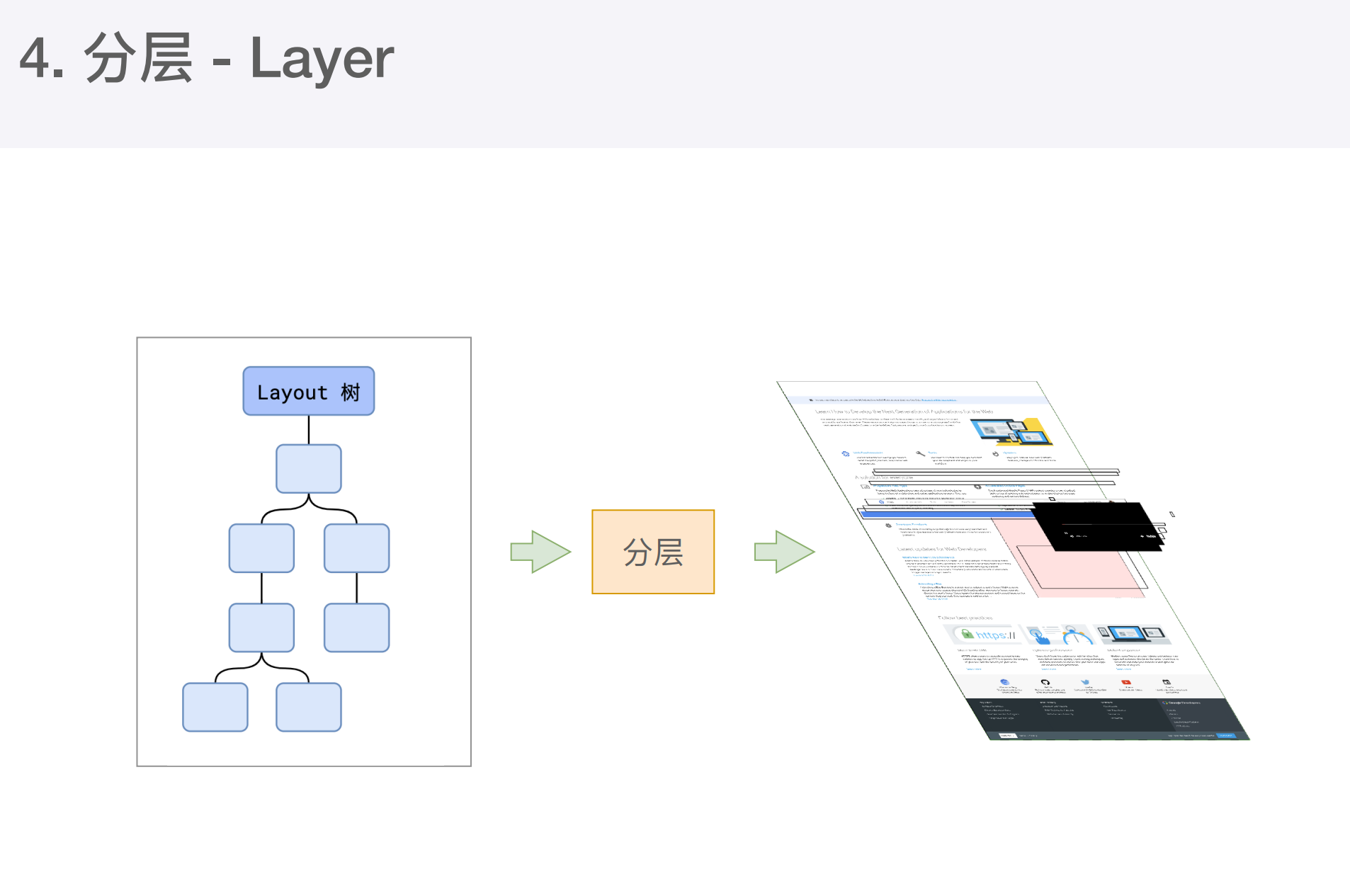
然后是分层
主线程会使用一套复杂的策略对整个布局树进行分层。
TIP
分层的好处就是,将来某一层改变后,仅会对该层进行后续处理,从而提升效率。
滚动条、堆叠上下文、transform、opacity等样式都会或者多少影响分层结果。也可以通过will-change属性更大程度影响分层结果
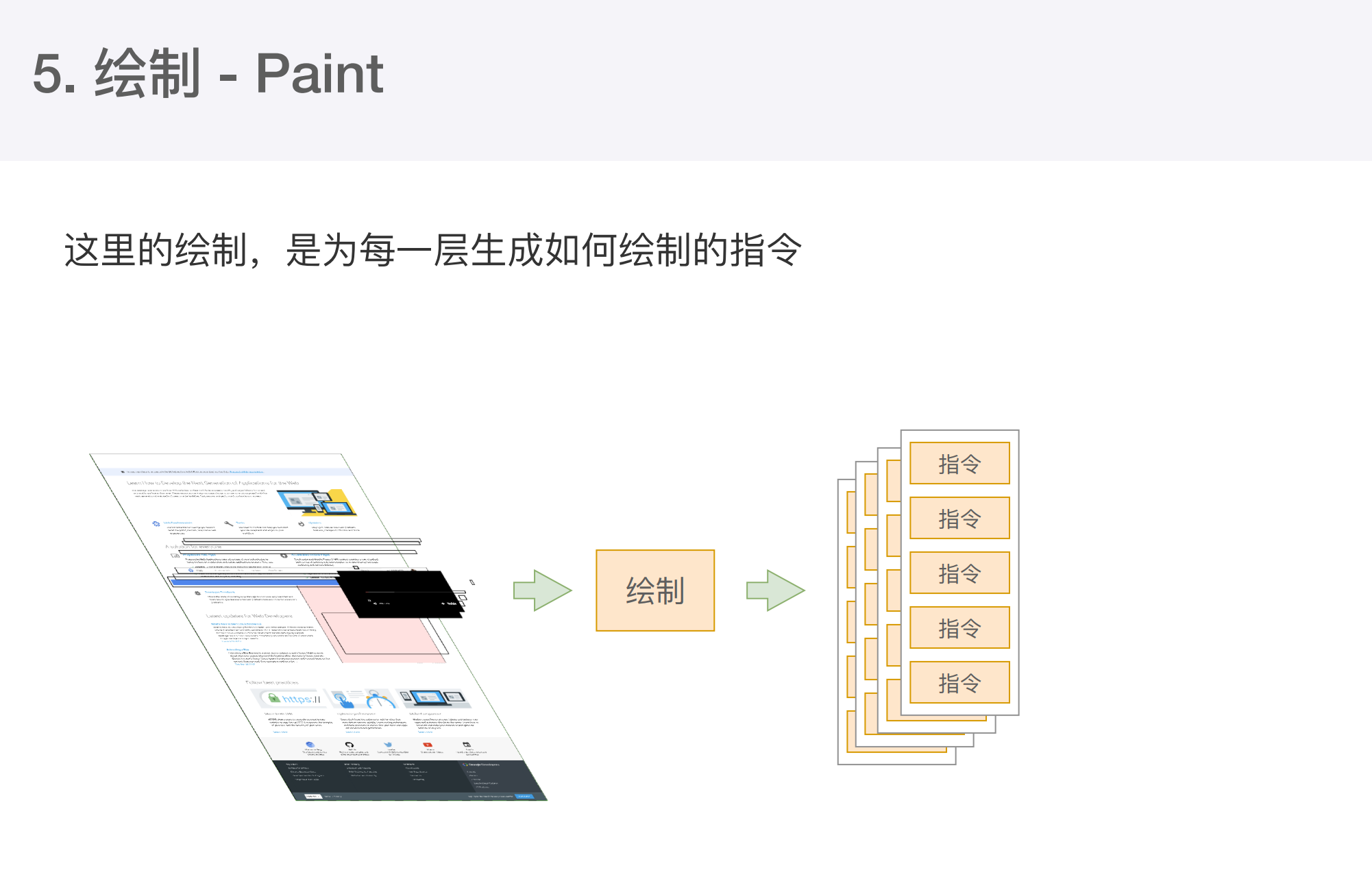
接下来绘制
- 主线程会为每个层单独产生绘制指令集,用于描述这一层的内容如何绘制。
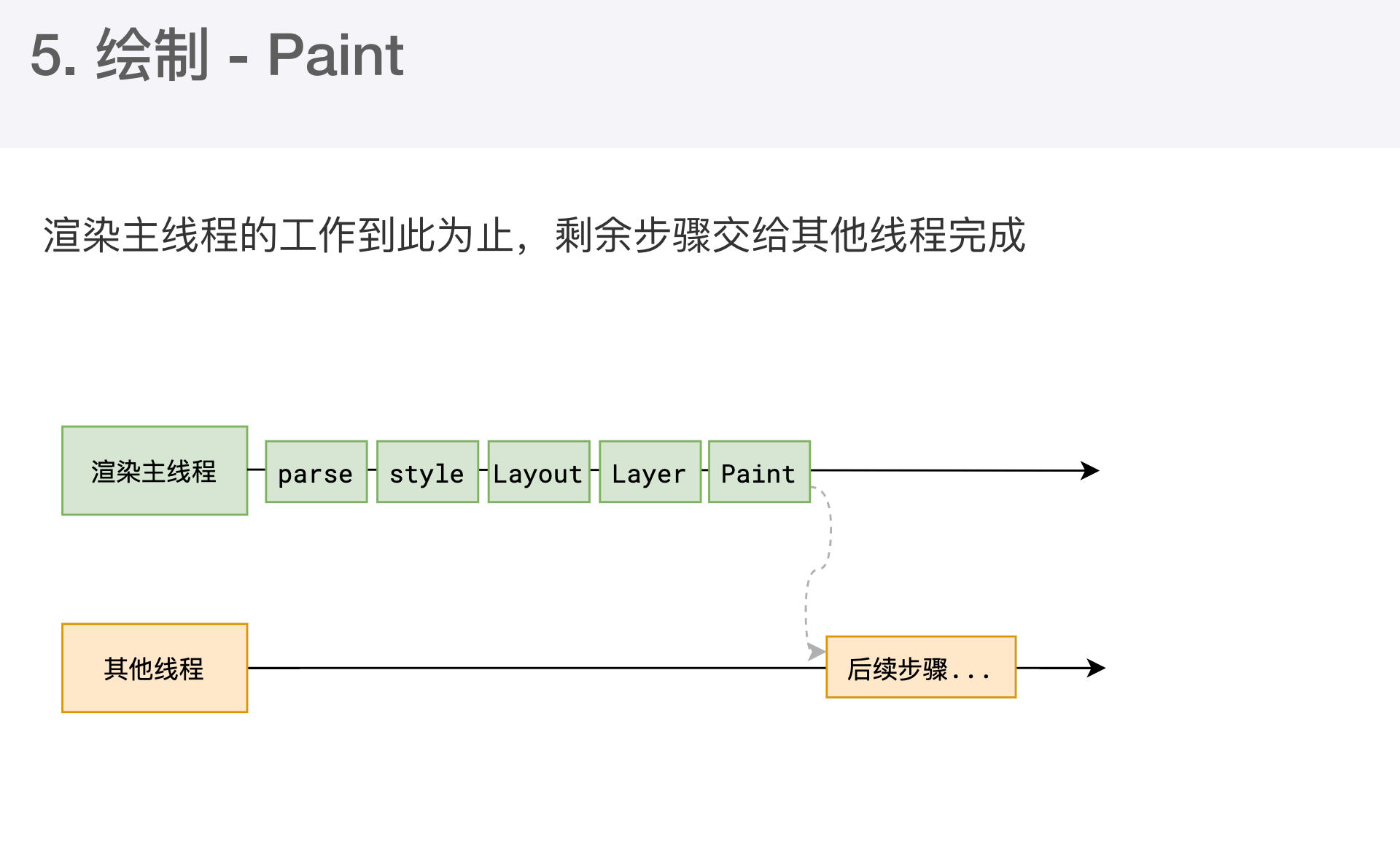
- 完成绘制后,主线程将每个图层的绘制信息提交给合成线程、剩余工作将由合成线程完成。
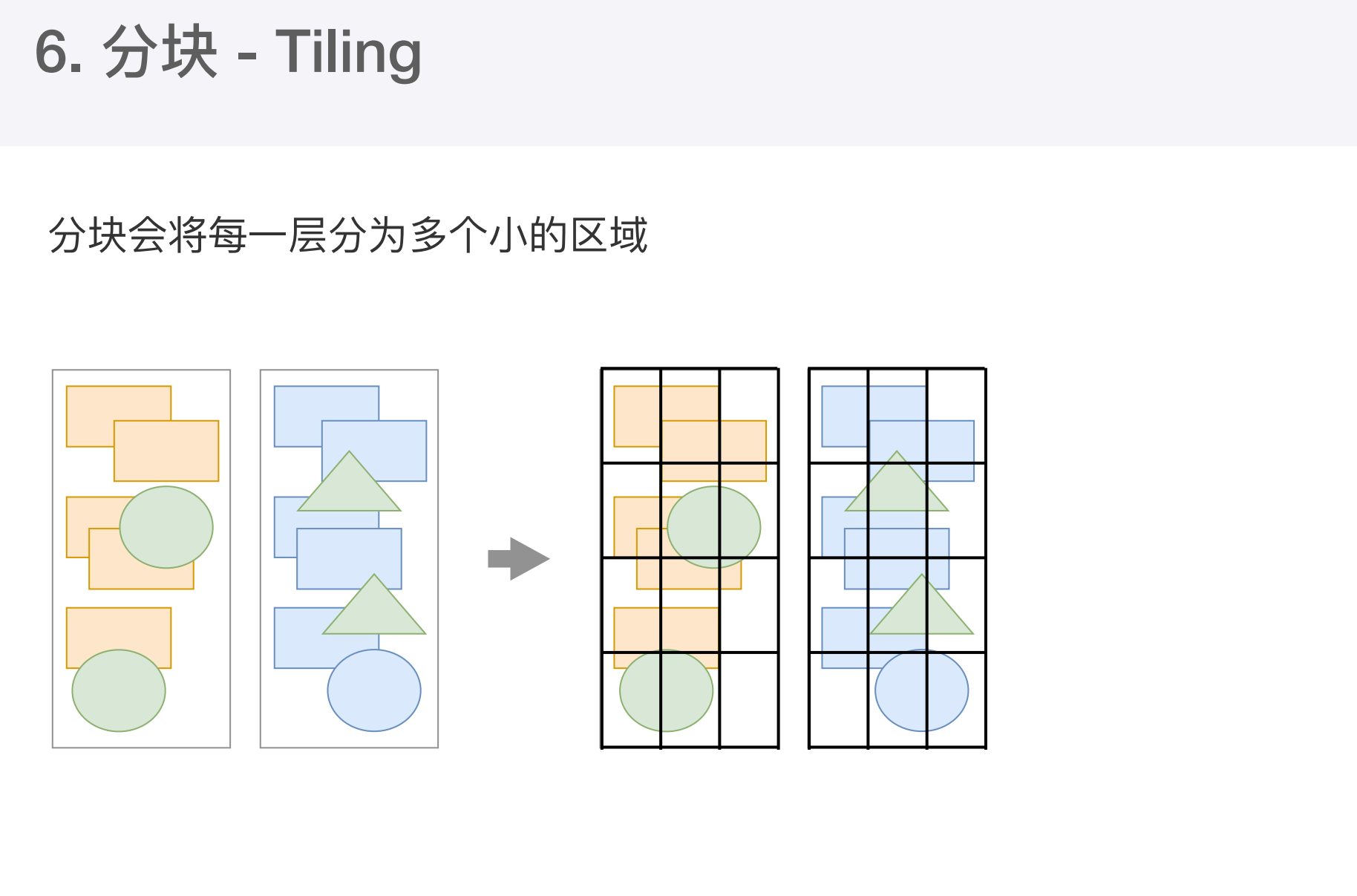
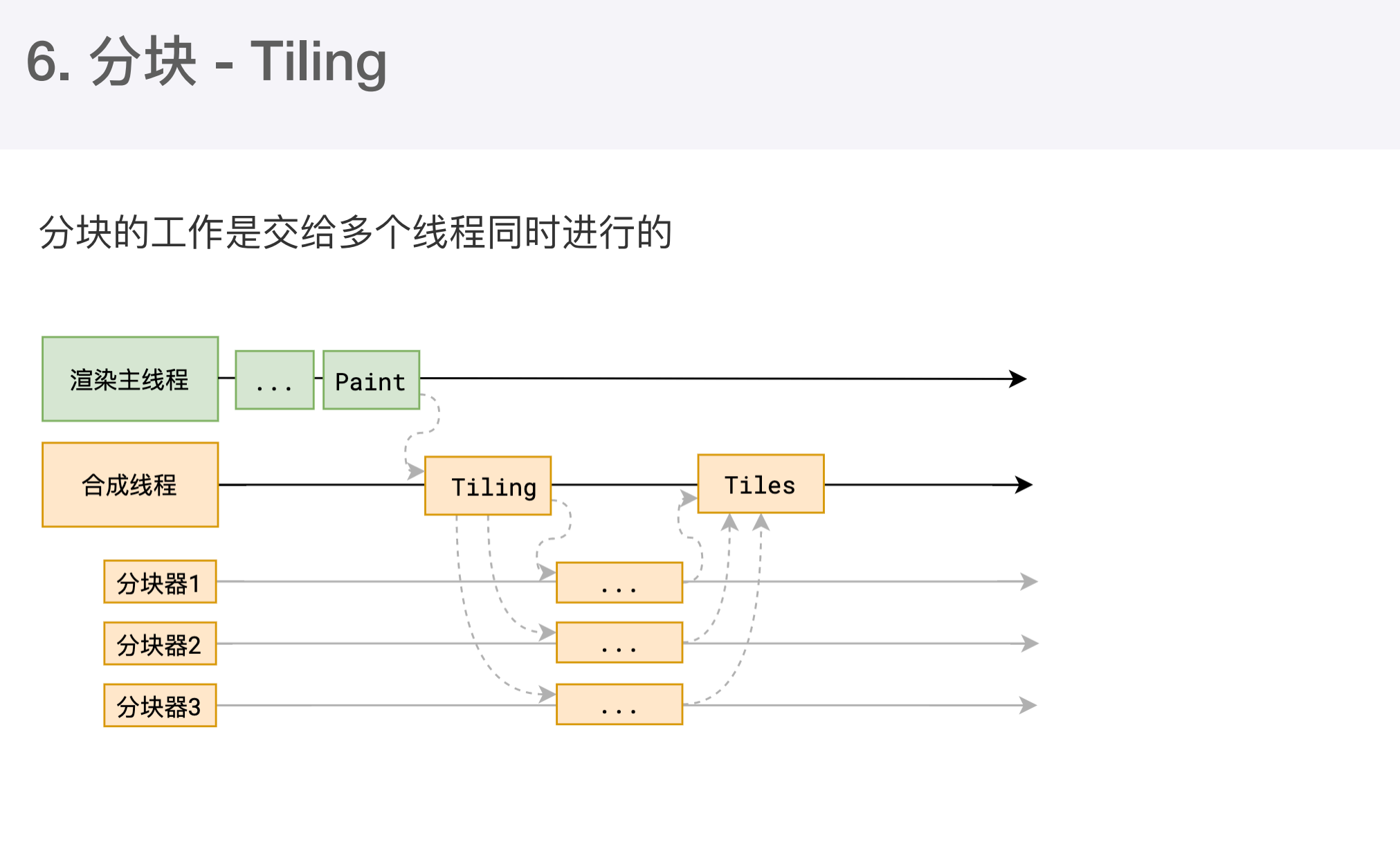
- 合成线程首先对每个图层进行分块,将其分成更小区域
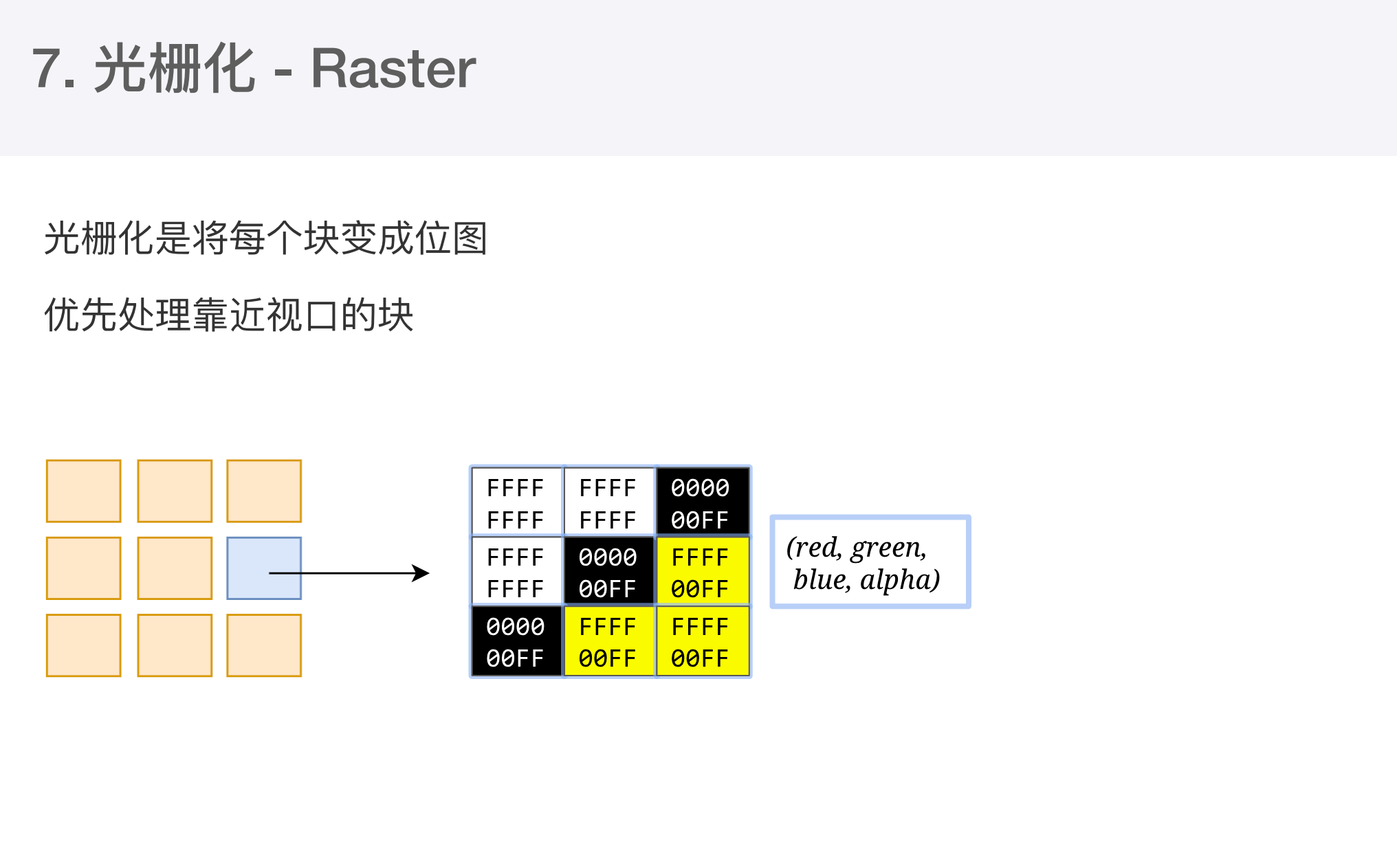
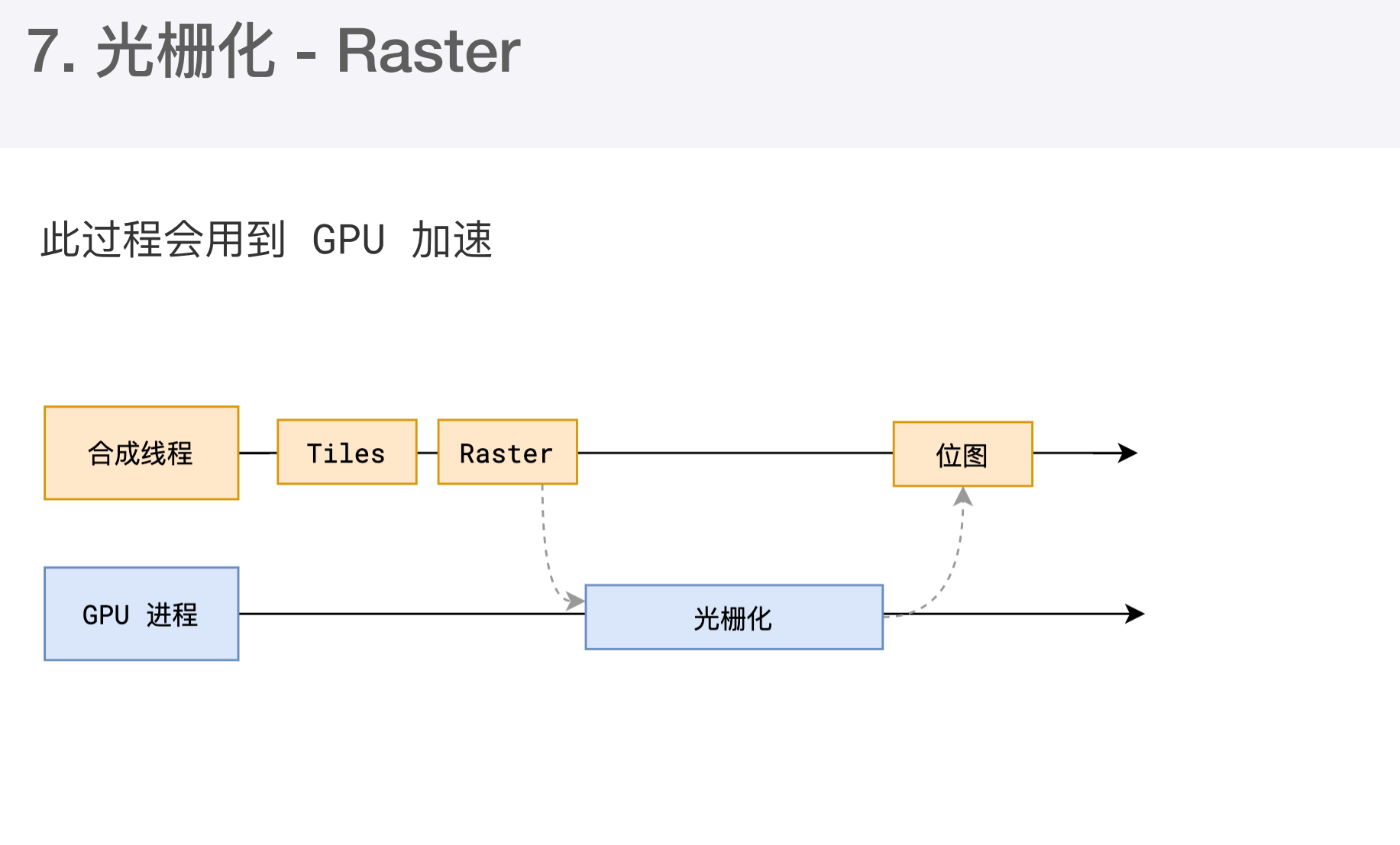
分块完成后会进行光栅化阶段。合成线程会将块信息交给 GPU进程,以极高速度完成光栅化。GPU进程会开启多个线程来完成光栅化,并且优先处理靠近视口区域的块,光栅化的结果就是一块一块的位图。
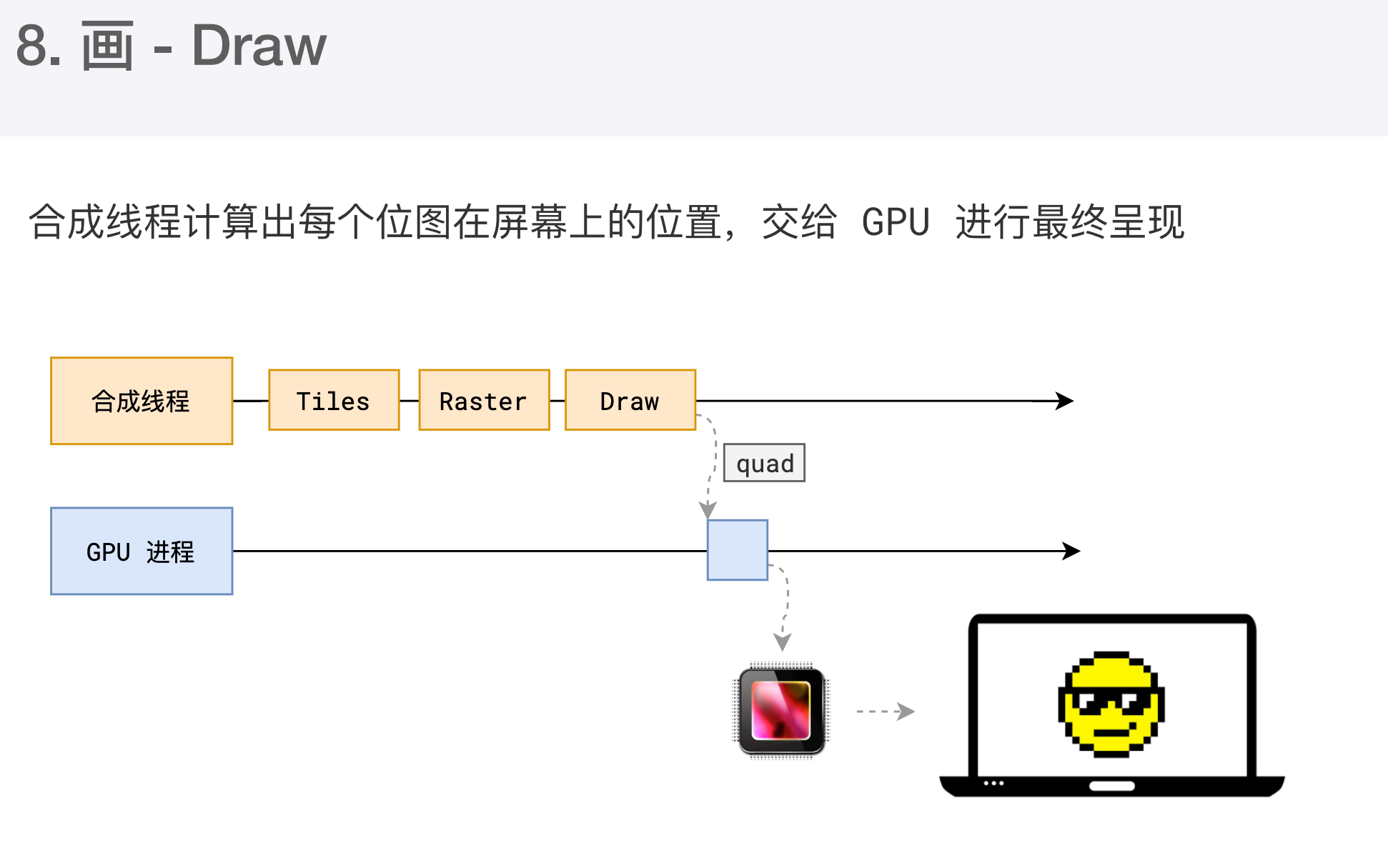
最后一个阶段:合成线程拿到每个层,每个块的位图后,生成一个个【指引(quad)】信息,指引会标识每个位图应该画到屏幕的哪个位置,以及会考虑到旋转缩放等变形。变形发生在合成线程,与渲染主线程无关,这就是transform效率高的原因。合成线程会把quad 提交给GPU进程,由GPU进程产生系统调用,提交给硬件,完成最终的屏幕成像。
# 1、解析html
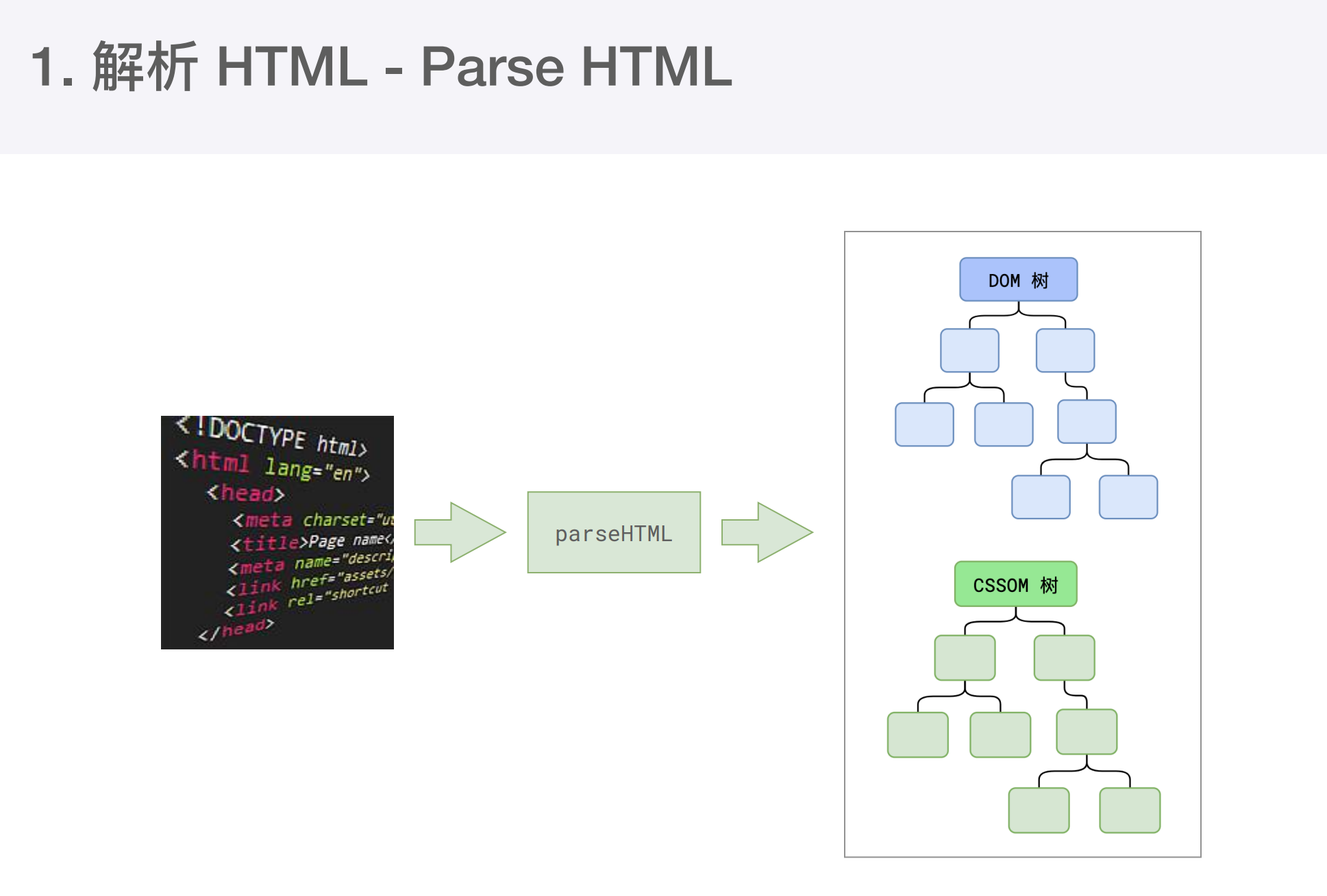
经过转换后 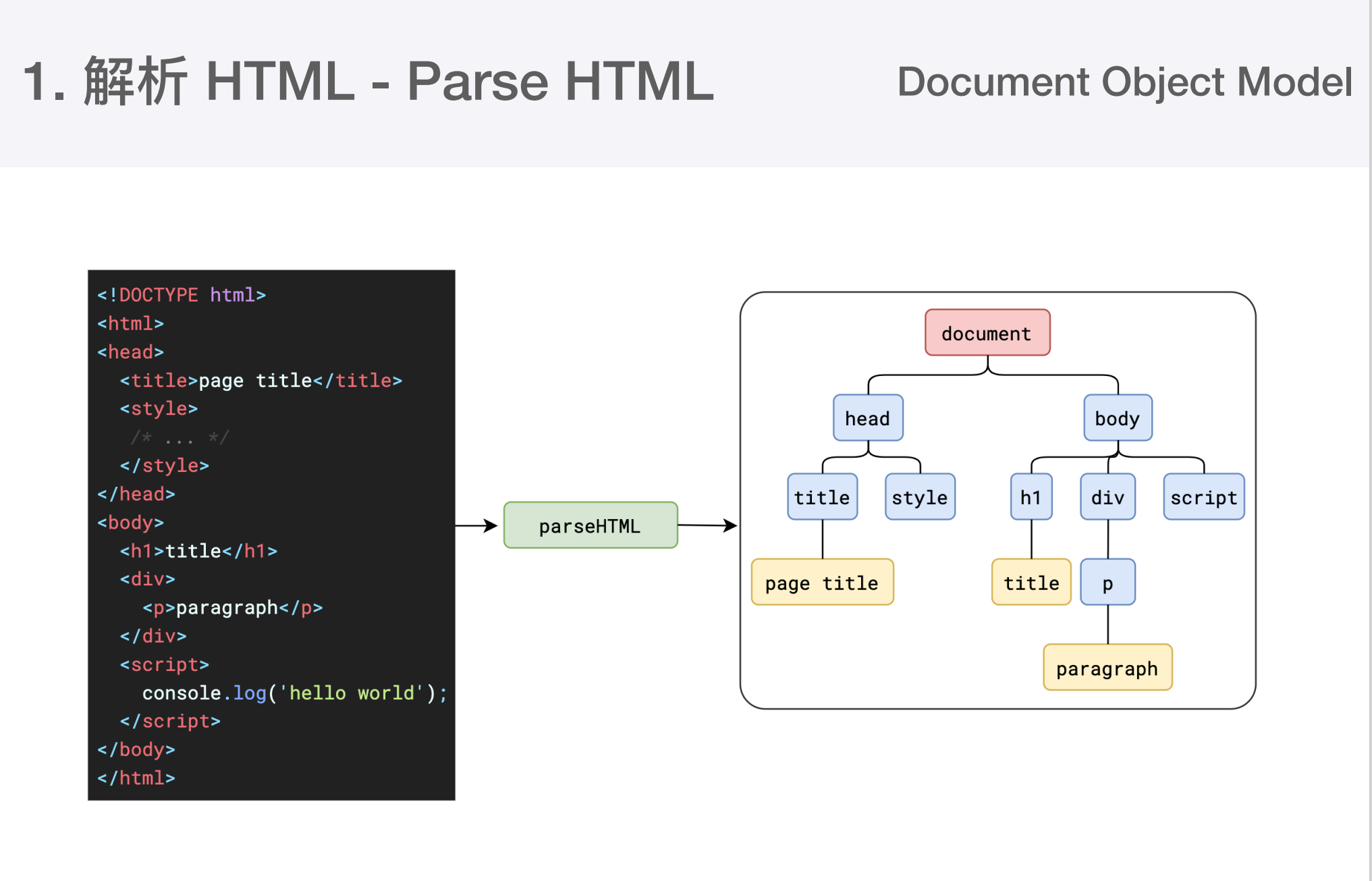
解析遇到js
# 2、样式计算
# 3、布局
# 4、分层
# 5、绘制
# 6、分块
# 7、光栅化
# 8、画
# 总结